I used an image from The Geological Society of America‘s “Time Scale” but this isn’t about that, but it kind of is and I’ll have a future post about using TimescaleDB to organize “Time Scale” like this, but that’ll be a little bit in the future. For now, I posted that Time Scale for the LOLz. 🤙🏻
I’ve been using TimescaleDB for time-series data on and off for a while now. I recently fired up Postgres.app for local development. It’s one of the cleanest ways to get PostgreSQL running on macOS, and adding TimescaleDB is surprisingly straightforward once you know where to look.
Time-series data is everywhere—sensor readings, application metrics, user events, IoT data. Regular PostgreSQL can handle it, but once you’re dealing with millions of rows, you’ll notice queries slowing down. TimescaleDB solves this by turning your time-series tables into hypertables that automatically partition by time, compress old data, and optimize queries. The best part? It’s still PostgreSQL, so all your existing tools and SQL knowledge work exactly the same.
I’ve built enough dashboards and monitoring systems to know when you need proper time-series handling versus when you can get away with a regular table and a good index. Once you’re dealing with millions of rows and need to query across time ranges efficiently, TimescaleDB is worth the setup.
Recently I created a video short on how to split out a timestamp column for Hasura. This included the SQL for Postgres via a schema migration and also details on how this appears in the Hasura user interface. You can check out the video here.
The break out of what I show in the video is available in a Github repository also.
Here is the specific database query that creates the table with the timestamp being broken out to the year, month, and day as generated column data.
create table standard_relational_model.users_data
(
user_id uuid PRIMARY KEY,
address_id uuid,
signup_date timestamp DEFAULT now(),
year int GENERATED ALWAYS AS (date_part('year', signup_date)) STORED,
month int GENERATED ALWAYS AS (date_part('month', signup_date)) STORED,
day int GENERATED ALWAYS AS (date_part('day', signup_date)) STORED,
points int,
details jsonb
);
In this SQL the signup_date column is the timestamp column that I want split out to year, month, and day. I’ve set it up with a default function call of now() just to seed the column and not require entry when inserting a new row. With that seed, then the generated columns of year, month, and day use the date_part() function to extract the particular value out of the signup_date column and store it in the respective column.
The other columns are just there for other references.
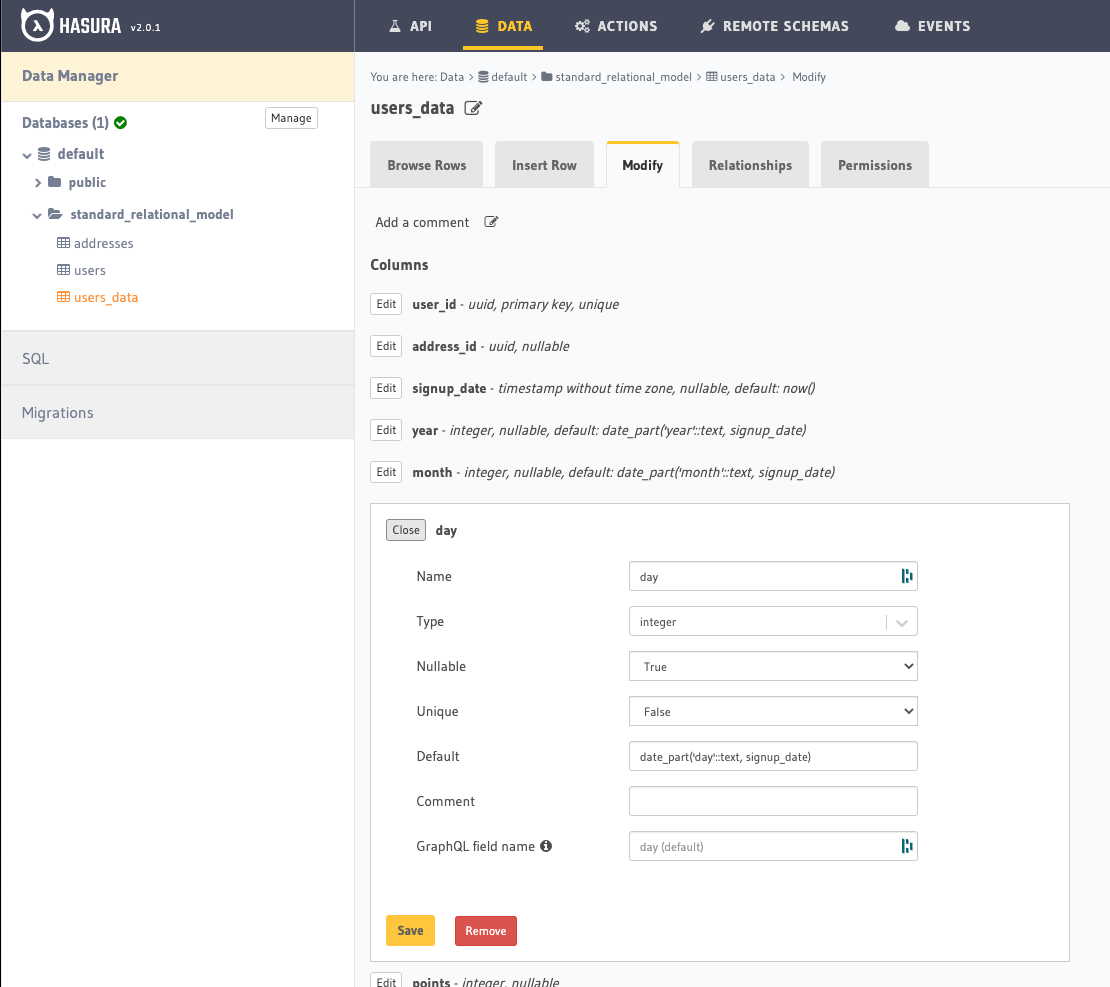
The Hasura Console
In the Hasura Console those columns would look something like this.
Notice the syntax displayed for these is different than the migration that created them.
date_part('day'::text, signup_date)
The above of course is for day, and each respective part is designated by month, year, etc.
When the data is added to the table the results return as follow with GraphQL and results.
GraphQL
The query.
query MyQuery {
users_data {
signup_date
year
month
day
}
}
This video shows the process detailed below in this blog entry, to provide the choice of video or a quick read! 👍🏻😁
I coded up some JavaScript to generate some data for a table recently and it seemed relatively useful, so here it is ready to use as you may. (The complete js file is below the description of the individual code segments below). This file simple data generation is something I put together to create a csv for some quick data imports into a database (Postgres, SQL Server, or anything you may want). With that in mind, I added the libraries and initialized the repo with the libraries I would need.
npm install faker
npm install fs
faker = require('faker');
fs = require('fs');
Next up I included the column row of data for the csv. I decided to go ahead and setup the variable at this point, as it would be needed as I would add the rest of the csv data to the variable itself. There is probably a faster way to do this, but this was the quickest path from the perspective of getting something working right now.
After the colum row, I also setup the base 8 UUIDs that would related to the project_id values to randomly use throughout data generation. The idea behind this is that the project_id values are the range of values that would be in the data that Subhendu would have, and all the ip and other recorded data would be recorded with and related to a specific project_id. I used a UUID generation site to generate these first 8 values, that site is available here.
After that I went ahead and added the for loop that would be used to step through and generate each record.
var data = "id,country,ip,created_at,updated_at,project_id\n";
let project_ids = [
'c16f6dd8-facb-406f-90d9-45529f4c8eb7',
'b6dcbc07-e237-402a-bf11-12bf2226c243',
'33f45cab-0e14-4830-a51c-fd44a62d1adc',
'5d390c9e-2cfa-471d-953d-f6727972aeba',
'd6ef3dfd-9596-4391-b0ef-3d7a8a1a6d10',
'e72c0ed8-d649-4c53-97c5-da793d7a8228',
'bf020fd2-2514-4709-8108-a2810e61c503',
'ead66a4a-968a-448c-a796-51c6a1da0c20'];
for (var i = 0; i < 500000; i++) {
// TODO: Generation will go here.
}
The next thing that I wanted to sort out are the two dates. One would be the created_at value and the other the updated_at value. The updated_at date needed to show as occurring after the created_at date, for obvious reasons. To make sure I could get this calculated I added a function to perform the randomization! First two functions to get additions for days and hours, then getting the random value to add for each, then getting the calculated dates.
function addDays(datetime, days) {
let date = new Date(datetime.valueOf());
date.setDate(date.getDate() + days);
return date;
}
function addHours(datetime, hours) {
let time = new Date(datetime.valueOf())
time.setTime(time.getTime() + (hours*60*60*1000));
return time;
}
var days = faker.datatype.number({min:0, max:7})
var hours = faker.datatype.number({min:0, max:24})
var updated_at = new Date(faker.date.past())
var created_at = addHours(addDays(updated_at, -days), -hours)
With the date time stamps setup for the row data generation I moved on to selecting the specific project_id for the row.
var proj_id = project_ids[faker.datatype.number({min:0, max: 7})]
One other thing that I knew I’d need to do is filter for the ' or , values located in the countries that would be selected. The way I clean that data to ensure it doesn’t break the SQL bulk import process is kind of cheap and in production data I wouldn’t do this, but it works great for generated data like this.
var cleanCountry = faker.address.country().replace(",", " ").replace("'", " ")
If you’re curious why I’m calculating these before I do the general data generation and set the row up, I like to keep the row of actual data calls to either a set variable assignment or at most one dot level deep in my calls. As you’ll see now in the row level data being generated below.
A video introduction into the basics of scaling a relational database like PostgreSQL.
There are two main ways to scale data storage, especially databases, and the resources available to store and process that data.
Horizontal Scaling (scale-out): This is done through adding more individual machines in some way, creating a cluster for the database to operate. Various databases handle this in different ways ranging from a system like a distributed database, which is specifically built to scale horizontally, to relational databases which require different strategies like sharding the data itself.
Vertical Scaling (scale-up): This includes increasing the individual system resources allocated to a database on a single vertically integrated machine, such as the CPU or number of CPUs, memory, and disk or disks.
For horizontal scaling the approach often requires things like possible sharding of the data across multiple databases and then pooling those resources together via connection pooling, load balancers, and other infrastructure resources to direct the correct requests and traffic at the right sharded database resource.
Sometimes from a purely process-centric horizontal scaling perspective, we just need more query and processing power but the data can be stored on a singular machine. In this case, we might implement a proxy to direct traffic across some bouncers that would then get requests and responses to and from the individual machines.
Vertical scaling often requires new hardware and a migration to the larger machine. Sometimes however it may just require more CPU, RAM, or more drive storage. If it is a singular need it often can be met by adding one of those elements or changing out one. For example, if a databases is continually hitting the peak processing of the CPUs to handle queries, one might be able to just add another processor or change the processor to a faster processor or one with more cores to process with. In the case of memory being overloaded, the same for that, simply increase the maximum memory in the system. Of course, the underlying limitations of vertical scaling always come up when you already have the fastest CPU or the memory is already maxed out. In that situation one might need to think about horizontally scaling as described in the previous described example.
The following is a top X list of blog entries that cover the expansion of the topic in many ways. I’ve found these (along with more than a few others) very useful in my own efforts around scaling Postgres (and other databases).





You must be logged in to post a comment.