
A few weeks ago I wrote up the post on the tech I’ve decided to move forward with for my new project. This post is going to cover the collection of features, domain details (i.e. what is the use case, etc), and related project collateral. Instead of just slinging code like many of us programmers often do, I’m going to layout what I’m trying to build, what features I want, and how I’m going to put those features together before delving into actual code. This way, my hope is I’ll be able to keep track over time better, and if any of this turns into something I’ll then have something to keep working from instead of throwing a code base over the fence to other devs. A crazy action that happens all the time, but is something worth avoiding!
Continue reading “Software Development: Getting Started by Getting Organized”Tag: github
Using Multiple SSH Keys for Multiple Github Account

FIRST – Setup the Keys
If there is already a key, I can use this one to start with, but if there is no key to start with I’ll need to generate one. I can do this with the following command:
ssh-keygen -t rsa
When generating the keys, best to go with the default location, which is ~/.ssh/id_rsa. This will create two files, id_rsa and id_rsa.pub. The id_rsa file is the private key, and the id_rsa.pub file is the public key. The private key should be kept secret, and the public key can be shared with anyone.
For the next account, which I’ll just call the work account, I’ll generate another new key. This time I’ll hand off the following parameters to the key generation to provide the work account email and the file name:
ssh-keygen -t rsa -C "adron.account@work_mail.com" -f "work_account_one"
I’ve now got two keys, one for my personal account and one for my work account.
~/.ssh/id_rsa
~/.ssh/work_account_one
I’ll need to add these to the ssh-agent and the respect Github (or git whatever servers) so that I can use them.
SECOND – Add the Keys to Github
Adding the keys to Github. We’ll start with the personal account and then add the work account. Copy the public key using pbcopy < ~/.ssh/id_rsa.pub. With that copied log into the Github account that this key should be associated with.
1. Got to *settings*.
2. Select *SSH and GPG keys* from the account user menu.
3. Navigate into `New SSH Key`, give it a title, and paste the key into the key field.
4. Click *Add SSH Key*.
Now log out of that Github account and into the other account, the work account. Repeat the steps above, but this time use the work account email and the work account key.
THIRD
Register the new keys with ssh-agent. Start by checking that the ssh-agent is running with eval "$(ssh-agent -s)". In the past we would add the keys to the agent with ssh-add -K ~/.ssh/id_rsa and ssh-add -K ~/.ssh/work_account_one. Now the keys are registered with the agent with the following.
ssh-add --apple-use-keychain ~/.ssh/id_rsa
ssh-add --apple-use-keychain ~/.ssh/work_account_one
FOURTH
There is one last step, I need to tell the ssh client which key to use for which account. I can do this by adding the following to the ~/.ssh/config file.
# Account 1 - Primary
Host github.com
HostName github.com
User git
IdentityFile ~/.ssh/id_rsa
AddKeysToAgent yes
UseKeychain yes
# Account 2 - Second Account
Host github.com-work_user_account_name
HostName github.com
User git
IdentityFile ~/.ssh/work_account_one
AddKeysToAgent yes
UseKeychain yes
Note that work_user_account_name is the name of the work account, not the email address. I can now use the following commands to clone repositories from the respective accounts. This tells ssh-agent to use the id_rsa key for Git URLs starting with github.com and the work_account_one key for Git URLs starting with github-work_user_account_name.
FIFTH
One active SSH key per working session.
This is a good practice to follow. I can use the following command to start the ssh-agent and add the key to it.
eval "$(ssh-agent -s)
ssh-add -K ~/.ssh/id_rsa
ssh-add ~/.ssh/id_rsa
The same can then be done when the other key needs to be used.
@ML4ALL Meet Clair J. Sullivan & Ricky Hennessy
 Using Machine Learning to Increase Health Insurance Coverage
Using Machine Learning to Increase Health Insurance Coverage
Ricky (@rickyhennessy) works as a Sr. Data Designer at Fjord, Design and Innovation from Accenture. Previously, he was at frog design, where he worked as a Sr. Data Scientist. Working at the intersection of data science and design, he’s been able to apply a more human centered approach to data science. He has also earned a PhD in biomedical engineering at UT Austin.
Working with a state run healthcare exchange, Ricky & team utilized their existing data to develop a machine learning model that could predict whether or not an individual was going to sign up for insurance through the exchange in the next open enrollment enrollment period. This model can then be used to inform outreach campaigns targeted at individuals at risk of dropping out of the exchange.
Continue reading “@ML4ALL Meet Clair J. Sullivan & Ricky Hennessy”
Coding on Orchestrate.io & Orchestrate.js & Orchestrate.NET
First context, then I’ll dive in.
Orchestrate
http://orchestrate.io/
![]() Orchestrate is a service that provides a simple API to access a multitude of database types all in one location. Key value, graph or events, some of the database types I’ve been using, are but a few they’ve already made available. There are many more on the way. Having these databases available via an API instead of needing to go through the arduous process of setting up and maintaining each database for each type of data structure is a massive time saver! On top of having a clean API and solid database platform and infrastructure Orchestrate has a number of client drivers that provide easy to use wrappers. These client drivers are available for a number of languages. Below I’ve written about two of these that I’ve been involved with in some way over the last couple of months.
Orchestrate is a service that provides a simple API to access a multitude of database types all in one location. Key value, graph or events, some of the database types I’ve been using, are but a few they’ve already made available. There are many more on the way. Having these databases available via an API instead of needing to go through the arduous process of setting up and maintaining each database for each type of data structure is a massive time saver! On top of having a clean API and solid database platform and infrastructure Orchestrate has a number of client drivers that provide easy to use wrappers. These client drivers are available for a number of languages. Below I’ve written about two of these that I’ve been involved with in some way over the last couple of months.
Orchestrate.NET
https://github.com/RobertSmith/Orchestrate.NET
This library I’m currently using for a demonstration application built against the Deconstructed.io services (follow us on twitter ya! @BeDeconstructed), a startup I’m co-founding. I’m not sure exactly what the app will be, but being .NET it’ll be something enterprisey. Because: .NET is Enterprise! For more on this project check out the Deconstructed.io Blog.
Some of the latest updates with this library.
- Just got everything fixed up and working with Visual Studio 2012 and Xamarin Studio with the latest Microsoft.Bcl.Build Libraries.
- The app.config is setup to just add your API key and run the tests for verification of the build. Integration tests and others.
- Project is now setup as a PCL or Portable Class Library for use with Xamarin and Android, iOS, Linux and related builds or w/ Visual Studio for Windows Phone and other related builds.
But there’s still a bit of work to do for the library, so consider this a call out for anybody that has a cycle they’d like to throw in on the project, let us know. We’d happily take a few more pull requests! The main two things we’d like to have done real soon are…
- Additional Documentation, Especially in the README.md with a few more examples of code here and there.
- More unit tests, especially one’s that are pure unit and not integration to help with any future refactoring of the code.
Orchestrate.js
https://github.com/orchestrate-io/orchestrate.js
With the latest fixes, additions and updates the orchestrate.js client driver is getting more feature rich by the day. In addition @housejester has created an orchestrate-brain project for Hubot that uses Orchestrate.js. If you’re not familiar with Hubot, but sure to check out the company robot that can dramatically improve and reduce employee efficiency! Keep an eye on that project for more great things, or create a Hubot to keep a robotic eye on the project.
Here are a few key things to note that have been added to help in day-to-day coding on the project.
- The travis.yml file has been added for the Travis Continuous Integration build. This build runs against node.js v0.10 and v0.8.
- Testing is done with mocha, expect.js and nock. To get the tests up and running, clone the repo and then build with the make file. The tests will run in tdd format.
- Promises are provided via the kew library.
If you’re opening up the project in WebStorm, it’s great to setup the mocha tests with the integrated mocha testing as shown below. After you’ve cloned the project and run ‘npm install’ then follow these steps to add the Mocha testing to the project. We’ve already setup exclusions in the .gitignore for the .idea directory and files that WebStorm uses.
First add a configuration by clicking on Edit Configurations.

Next click on the + to add a new configuration to run. Select the Mocha option from the list of configurations.

On the next screen set a name for the configuration. Set the test directory to the path for the test directory in the project. Then finally set the User interface option for Mocha to TDD instead of the default BDD.

Last but not least run the tests and you’ll see the list of green lights light up the display with positive results.

Bringing to Life an Open Source Software Project via Github & Jekyll – Part 1
Starting with Github, Automatic Page Generation & Jekyll
It’s time for another blog series! This is a series I’m starting to outline that crazy complex site I’m building to prove out all sorts of things, all located at http://adron.me. So far it’s just a site that hold portfolio information for my coding, biking and related information about me. However I’m using this as a base template, that anybody can use via the github repo I’ve created simply titled Me, to start and scale their own personal site. But beyond that, I’ll be using practices and technology that can be used to truly scale large sites with lots of users. If you have any questions, comments or suggestions about this series please ping me on Twitter @adron or leave a comment on this blog itself.
First things first, let’s get our git repository setup on github with the appropriate issues list, and project page via gh-pages (jekyll).
Create a new github project.

Next we’ll have the site created and github will display the repository page. On this page you can see that the README.md and .gitignore file have been created with some basic defaults for a Node.js Project. At the top right click on the Settings button to navigate to the settings page.
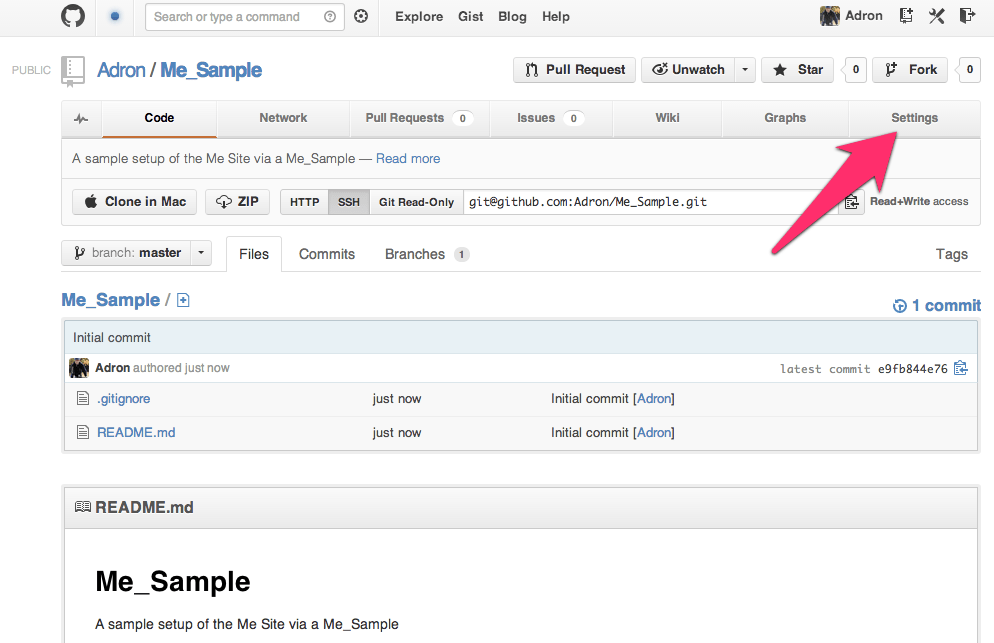
On the settings page scroll down until you see the section for Github Pages with the Automatic Page Generator button. Click that button.
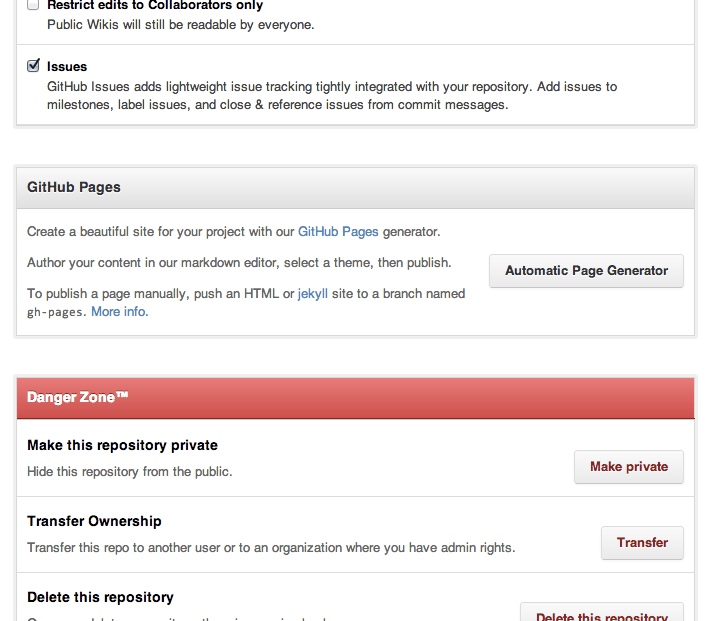
You’ll be directed to create a page, with default data as shown below.
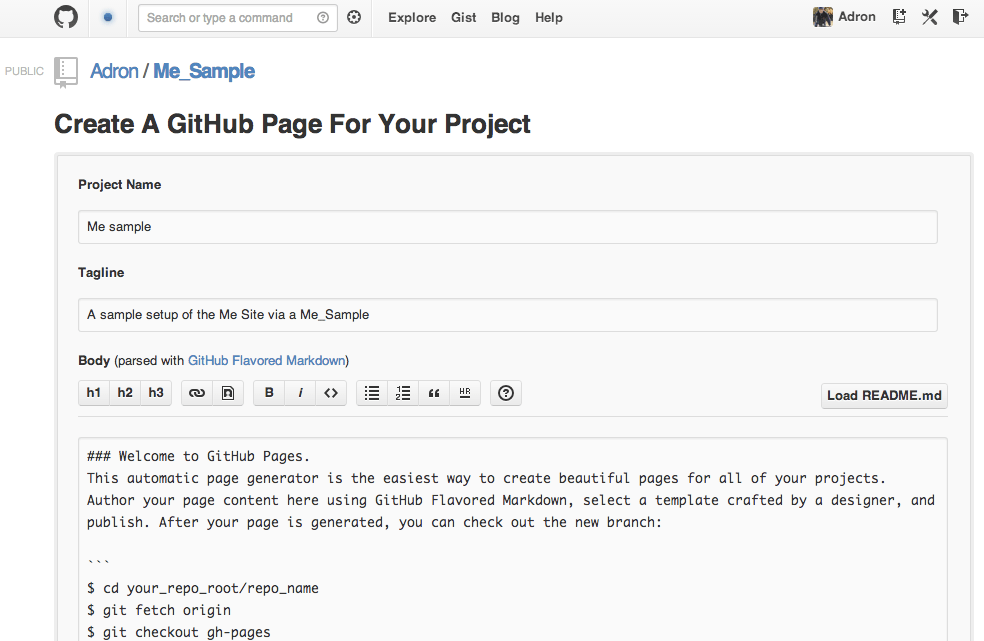
Scroll down on this page and click to create the automatically generated page. You’ll be sent to the page to select a theme. I just went with the default since I’ll delete it later to create the Jeckyll project page instead. Click on publish on this screen.
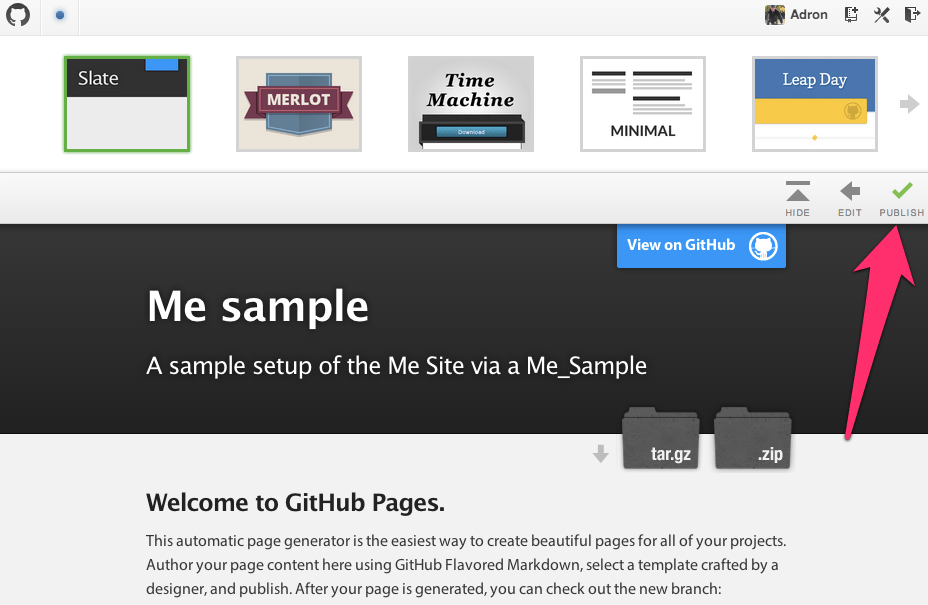
Once this page generates you’ll be directed back to the github repository again. At the top of the page there will be a link to the newly generated page. You can click on this to navigate to it and see what it looks like. Also note that the new repository branch which is named gh-pages is not displayed. This new branch includes all of the files for this Github Pages project page.
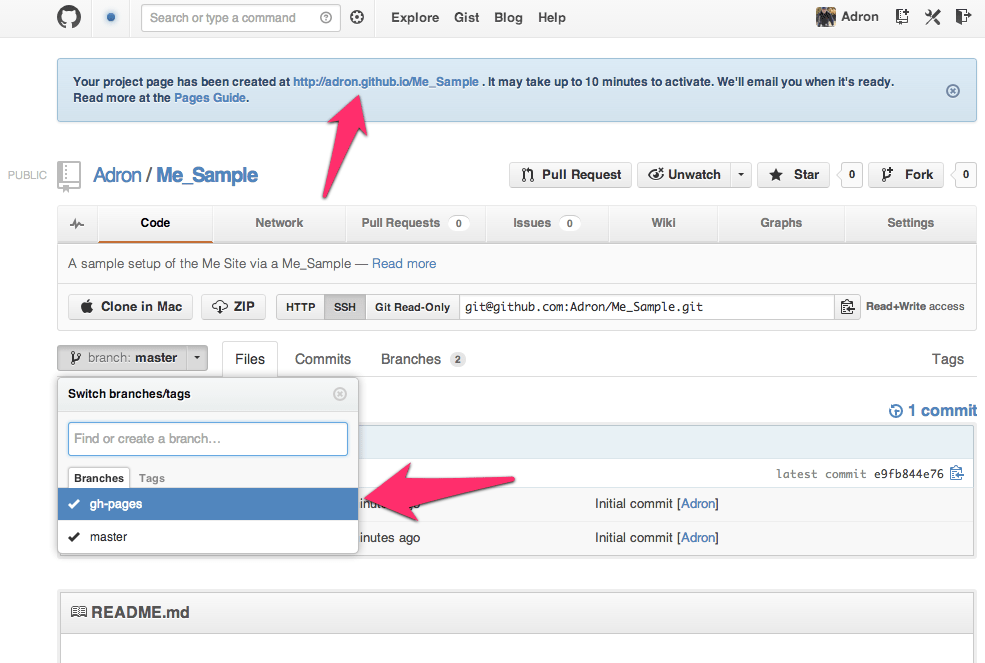
Change the branch to the gh-pages branch and you’ll see that the branch has entirely different files than the master branch.
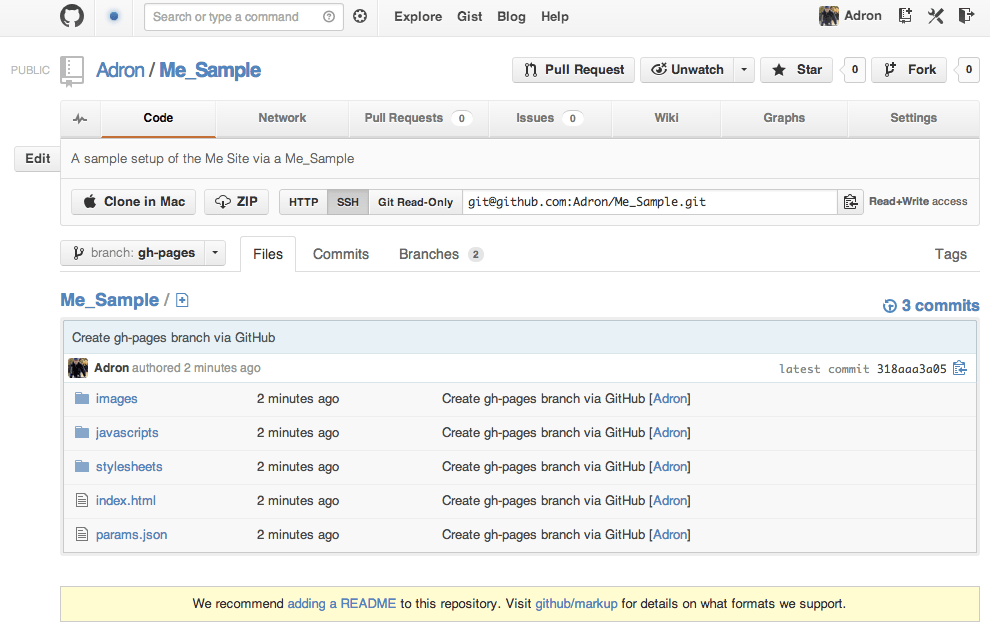
If you click on the link at the top of the page, you’ll see where the current automatically generated page is and where the future jekyll site we’ll build will be located at. This page that was generated (unless you chose another theme) will look like this.

Now we have an appropriate branch and we’re ready to toss a jeckyll project in its place. However, if a default template and related content works for your project, that’s a great way to go with it. However some projects may want a blog or other content, just a bit more the default generated page, and this is what we’ll create with this jeckyll site. It’s also very easy to create a jeckyll site and create an image portfolio or a host of other types of sites, all backed by a git repository on github. I’ll keep moving now, on to the jeckyll site!
A Github Jeckyll Site
First get a clone of the site that was generated in the above instructions.
[sourcecode language=”bash”]
git clone git@github.com:Adron/Me.git
[/sourcecode]
Now we have a good working directory where this is cloned at. First switch branches to the gh-pages branch. Get a list of all branches (the -a switch shows all branches, even the remote branches).
[sourcecode language=”bash”]
git branch -a
[/sourcecode]
The results will display with the full branch names for the remote branches.
[sourcecode language=”bash”]
git branch -a
* master
remotes/origin/HEAD -> origin/master
remotes/origin/gh-pages
remotes/origin/master
remotes/origin/theme-all-by-itself
[/sourcecode]
The asterisks shows the current active branch. The branch that needs edited is the remotes/origin/gh-pages branch. Check it out with the following command.
[sourcecode language=”bash”]
git checkout remotes/origin/gh-pages
[/sourcecode]
Which will then print out the following content.
[sourcecode language=”bash”]
Note: checking out ‘remotes/origin/gh-pages’.
You are in ‘detached HEAD’ state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b new_branch_name
HEAD is now at d430b0c… … etc. etc…
[/sourcecode]
What this basically means is, we have a branch that is disconnected and not attached to the repository in any way. To fix this we’ll create a working local branch to work with the remotes/origin/gh-pages branch. Do this with the following command.
[sourcecode language=”bash”]
git branch gh-pages
[/sourcecode]
Then if you get a list of the existing local branches the master and gh-pages branches will be available locally.
[sourcecode language=”bash”]
git branch
* (no branch)
gh-pages
master
[/sourcecode]
Now switch to that branch. Since we’re currently on (No branch) this content will be switched to the local gh-pages branch wit the following command.
[sourcecode language=”bash”]
git checkout gh-pages
[/sourcecode]
Now delete all those files in that directory that github automatically created. In their place add a README.md and .gitignore file. In the commands below I’m using Sublime Text 2 command line tooling to open up the files into memory with Sublime Text 2.
[sourcecode language=”bash”]
subl .gitignore
[/sourcecode]
Add the following content to the .gitignore file.
[sourcecode language=”bash”]
_site/
*.DS_Store
.DS_Store
[/sourcecode]
Save that file. Create the README.md and…
[sourcecode language=”bash”]
subl README.md
[/sourcecode]
…add some content to it.
[sourcecode language=”bash”]
My Awesome Header
===
Description: An appropriate description.
Documentation
—
Dammit, WRITE YOUR DOCUMENTATION!!!!
[/sourcecode]
I added a little mark down for that README.md example just so there is something more than just text displaying.
Add these files to the local repository, committing and then pushing them up to the remote gh-pages repository.
[sourcecode language=”bash”]
git add -A
git commit -m ‘Adding initial .gitignore and README.md content.’
git push origin gh-pages
[/sourcecode]
Now in this directory we’re about to get things kicking for Jeckyll. First, get Jeckyll.
[sourcecode language=”bash”]
sudo gem install jeckyll
[/sourcecode]
For your specific OS you may want to check out the actual jeckyll repository installation instructions. There is more of a break down of various operating system needs for use.
Once it is installed, we’re now ready to use jeckyll to generate static content and even run the jeckyll server to view what our site looks like locally. Now let’s get some content together that jeckyll will know how to statically generate for viewing.
Create a folder called “_layouts” in the local repository. With the “_” at the beginning of the directory, it will not be generated into the static content by jekyll, but the convention is for the _layouts directory to include the templates for creating a standard layout for the rest of the pages in the site.
[sourcecode language=”bash”]
mkdir _layouts
[/sourcecode]
After creating the new folder, create a default.html inside the folder.
[sourcecode language=”html”]
<!DOCTYPE html>
<html>
<head>
<meta charset=utf-8 />
<title> {% if page.title %} {{ page.title }} | {% endif %} Adron Hall</title>
<link rel="stylesheet" href="css/styles.css" />
</head>
<body>
<div id="main">
<header>
<h1> Adron’s Github Project Pages </h1>
<header>
<nav role="navigation">
<ul>
<li><a href="/">Home</a></li>
<li><a href="/about">About</a></li>
<li><a href="/contact">Contact</a></li>
</ul>
</nav>
{{ content }}
<footer>
<p>© Adron’s Github Project Pages 2013 | All Rights Reserved. </p>
</footer>
</div>
</body>
</html>
[/sourcecode]
In the above HTML the {{ page.title }} item is a template variable that will display the title of the page when it is generated into static content by jekyll. Once this is created add an index.html page to the root path of the repository.
[sourcecode language=”bash”]
subl index.html
[/sourcecode]
Now add the following content to the index.html page and save it.
[sourcecode language=”html”]
—
layout: default
—
<section role="banner">
The banner will go here eventually.
</section>
<section class="content">
<p>
Welcome to Adron Hall’s Github Project Pages all manually created with jekyll!! Please, check out the blog at <a href="http://compositecode.com">Composite Code</a>!
</p>
</section>
[/sourcecode]
Now create a stylesheet and respective static directory for it.
[sourcecode language=”bash”]
mkdir css
[/sourcecode]
Create a styles.css file and add the following content that Dave Gamache created. I’ve included it below with all the appropriate licensing information and related content. Save this file when done.
[sourcecode language=”HTML”]
/*
* Skeleton V1.1
* Copyright 2011, Dave Gamache
* http://www.getskeleton.com
* Free to use under the MIT license.
* http://www.opensource.org/licenses/mit-license.php
* 8/17/2011
*/
/* Table of Content
==================================================
#Reset & Basics
#Basic Styles
#Site Styles
#Typography
#Links
#Lists
#Images
#Buttons
#Tabs
#Forms
#Misc */
/* #Reset & Basics (Inspired by E. Meyers)
================================================== */
html, body, div, span, applet, object, iframe, h1, h2, h3, h4, h5, h6, p, blockquote, pre, a, abbr, acronym, address, big, cite, code, del, dfn, em, img, ins, kbd, q, s, samp, small, strike, strong, sub, sup, tt, var, b, u, i, center, dl, dt, dd, ol, ul, li, fieldset, form, label, legend, table, caption, tbody, tfoot, thead, tr, th, td, article, aside, canvas, details, embed, figure, figcaption, footer, header, hgroup, menu, nav, output, ruby, section, summary, time, mark, audio, video {
border: 0 none;
font: inherit;
margin: 0;
padding: 0;
vertical-align: baseline;
}
article, aside, details, figcaption, figure, footer, header, hgroup, menu, nav, section {
display: block;
}
body {
line-height: 18px;
}
ol, ul {
list-style: none; }
blockquote, q {
quotes: none; }
blockquote:before, blockquote:after,
q:before, q:after {
content: ”;
content: none; }
table {
border-collapse: collapse;
border-spacing: 0; }
/* #Basic Styles
================================================== */
body {
background: url(../images/body_bg.png) repeat;
font-family: ‘Dosis’, sans-serif;
font-size:14px;
font-weight:500;
color:#E8E8E8;
text-shadow:0 1px 0 rgba(0, 0, 0, 0.7);
-webkit-font-smoothing: antialiased; /* Fix for webkit rendering */
-webkit-text-size-adjust: 100%;
}
.max-image { width:100%; height:auto; }
/* #Typography
================================================== */
h1, h2, h3, h4, h5, h6 {font-weight: normal;}
h1 a, h2 a, h3 a, h4 a, h5 a, h6 a { font-weight: inherit; }
h1 { font-size: 26px; line-height: 22px; margin-bottom: 14px; color:#FFCC00;}
h2 { font-size: 20px; line-height: 24px; margin-bottom: 10px; color:#FFF; font-weight:600; }
h3 { font-size: 16px; line-height: 22px; margin-bottom: 10px; color:#FFF; }
h4 { font-size: 15px; line-height: 20px; margin-bottom: 4px; color:#bc4444; }
h5 { font-size: 14px; line-height: 24px; }
h6 { font-size: 14px; line-height: 21px; }
.subheader { color: #777; }
p { margin: 0 0 20px 0; }
p img { margin: 0; }
p.lead { font-size: 21px; line-height: 27px; color: #777; }
em { font-style: italic; }
strong { font-weight: bold; color: #333; }
small { font-size: 80%; }
/* Blockquotes */
blockquote, blockquote p { font-size: 18px; line-height: 24px; color: #333; }
blockquote { margin: 0; padding: 0 20px 0 20px; border-left: 2px solid #F87536; }
blockquote cite { display: block; color: #ff8a00; }
blockquote cite:before { content: "\2014 \0020"; }
blockquote cite a, blockquote cite a:visited, blockquote cite a:visited { color: #555; }
hr { border: solid #ddd; border-width: 1px 0 0; clear: both; margin: 10px 0 30px; height: 0; }
/* #Links
================================================== */
a, a:visited { color: #f35f2a; text-decoration: none; outline: 0; }
a:hover, a:focus { color: #FFF; }
p a, p a:visited { line-height: inherit; }
/* #Lists
================================================== */
ul, ol { margin-bottom: 20px; }
ul { list-style: none outside; }
ol { list-style: decimal; }
ol, ul.square, ul.circle, ul.disc { margin-left: 30px; }
ul.square { list-style: square outside; }
ul.circle { list-style: circle outside; }
ul.disc { list-style: disc outside; }
ul ul, ul ol,
ol ol, ol ul { margin: 4px 0 5px 30px; font-size: 90%; }
ul ul li, ul ol li,
ol ol li, ol ul li { margin-bottom: 6px; }
li { line-height: 18px; margin-bottom: 12px; }
ul.large li { line-height: 21px; }
li p { line-height: 21px; }
/* #Images
================================================== */
img.scale-with-grid {
max-width: 100%;
height: auto; }
/* #Buttons
================================================== */
/*.button,
button,
input[type="submit"],
input[type="reset"],
input[type="button"] {
background: #3973a6; Old browsers
background: #3973a6 -moz-linear-gradient(top, rgba(255,255,255,.2) 0%, rgba(0,0,0,.2) 100%); FF3.6+
background: #3973a6 -webkit-gradient(linear, left top, left bottom, color-stop(0%,rgba(255,255,255,.2)), color-stop(100%,rgba(0,0,0,.2))); Chrome,Safari4+
background: #3973a6 -webkit-linear-gradient(top, rgba(255,255,255,.2) 0%,rgba(0,0,0,.2) 100%); Chrome10+,Safari5.1+
background: #3973a6 -o-linear-gradient(top, rgba(255,255,255,.2) 0%,rgba(0,0,0,.2) 100%); Opera11.10+
background: #3973a6 -ms-linear-gradient(top, rgba(255,255,255,.2) 0%,rgba(0,0,0,.2) 100%); IE10+
background: #3973a6 linear-gradient(top, rgba(255,255,255,.2) 0%,rgba(0,0,0,.2) 100%); W3C
border: 1px solid #3973a6;
border-top: 1px solid #3973a6;
border-left: 1px solid #3973a6;
color: #FFF;
display: inline-block;
font-size: 12px;
font-weight: bold;
text-decoration: none;
text-shadow: 0 1px rgba(33, 77, 121, .75);
cursor: pointer;
margin-bottom: 20px;
line-height: normal;
padding: 8px 10px; }
.button:hover,
button:hover,
input[type="submit"]:hover,
input[type="reset"]:hover,
input[type="button"]:hover {
color: #222;
background: #FF8A00; Old browsers
background: #FF8A00 -moz-linear-gradient(top, rgba(255,255,255,.3) 0%, rgba(0,0,0,.3) 100%); FF3.6+
background: #FF8A00 -webkit-gradient(linear, left top, left bottom, color-stop(0%,rgba(255,255,255,.3)), color-stop(100%,rgba(0,0,0,.3))); Chrome,Safari4+
background: #FF8A00 -webkit-linear-gradient(top, rgba(255,255,255,.3) 0%,rgba(0,0,0,.3) 100%); Chrome10+,Safari5.1+
background: #FF8A00 -o-linear-gradient(top, rgba(255,255,255,.3) 0%,rgba(0,0,0,.3) 100%); Opera11.10+
background: #FF8A00 -ms-linear-gradient(top, rgba(255,255,255,.3) 0%,rgba(0,0,0,.3) 100%); IE10+
background: #FF8A00 linear-gradient(top, rgba(255,255,255,.3) 0%,rgba(0,0,0,.3) 100%); W3C
border: 1px solid #888;
border-top: 1px solid #aaa;
border-left: 1px solid #aaa; }
.button:active,
button:active,
input[type="submit"]:active,
input[type="reset"]:active,
input[type="button"]:active {
border: 1px solid #666;
background: #ccc; Old browsers
background: #ccc -moz-linear-gradient(top, rgba(255,255,255,.35) 0%, rgba(10,10,10,.4) 100%); FF3.6+
background: #ccc -webkit-gradient(linear, left top, left bottom, color-stop(0%,rgba(255,255,255,.35)), color-stop(100%,rgba(10,10,10,.4))); Chrome,Safari4+
background: #ccc -webkit-linear-gradient(top, rgba(255,255,255,.35) 0%,rgba(10,10,10,.4) 100%); Chrome10+,Safari5.1+
background: #ccc -o-linear-gradient(top, rgba(255,255,255,.35) 0%,rgba(10,10,10,.4) 100%); Opera11.10+
background: #ccc -ms-linear-gradient(top, rgba(255,255,255,.35) 0%,rgba(10,10,10,.4) 100%); IE10+
background: #ccc linear-gradient(top, rgba(255,255,255,.35) 0%,rgba(10,10,10,.4) 100%); W3C }
.button.full-width,
button.full-width,
input[type="submit"].full-width,
input[type="reset"].full-width,
input[type="button"].full-width {
width: 100%;
padding-left: 0 !important;
padding-right: 0 !important;
text-align: center; }
Fix for odd Mozilla border & padding issues
button::-moz-focus-inner,
input::-moz-focus-inner {
border: 0;
padding: 0;
}*/
/* #Tabs (activate in tabs.js)
================================================== */
/*ul.tabs {
display: block;
margin: 0 0 20px 0;
padding: 0;
border-bottom: solid 1px #ddd; }
ul.tabs li {
display: block;
width: auto;
height: 30px;
padding: 0;
float: left;
margin-bottom: 0; }
ul.tabs li a {
display: block;
text-decoration: none;
width: auto;
height: 29px;
padding: 0px 20px;
line-height: 30px;
border: solid 1px #ddd;
border-width: 1px 1px 0 0;
margin: 0;
background: #f5f5f5;
font-size: 13px; }
ul.tabs li a.active {
background: #fff;
height: 30px;
position: relative;
top: -4px;
padding-top: 4px;
border-left-width: 1px;
margin: 0 0 0 -1px;
color: #111;
-moz-border-radius-topleft: 2px;
-webkit-border-top-left-radius: 2px;
border-top-left-radius: 2px;
-moz-border-radius-topright: 2px;
-webkit-border-top-right-radius: 2px;
border-top-right-radius: 2px; }
ul.tabs li:first-child a.active {
margin-left: 0; }
ul.tabs li:first-child a {
border-width: 1px 1px 0 1px;
-moz-border-radius-topleft: 2px;
-webkit-border-top-left-radius: 2px;
border-top-left-radius: 2px; }
ul.tabs li:last-child a {
-moz-border-radius-topright: 2px;
-webkit-border-top-right-radius: 2px;
border-top-right-radius: 2px; }
ul.tabs-content { margin: 0; display: block; }
ul.tabs-content > li { display:none; }
ul.tabs-content > li.active { display: block; }
/* Clearfixing tabs for beautiful stacking */
/*ul.tabs:before,
ul.tabs:after {
content: ‘\0020’;
display: block;
overflow: hidden;
visibility: hidden;
width: 0;
height: 0; }
ul.tabs:after {
clear: both; }
ul.tabs {
zoom: 1; }*/*/
/* #Forms
================================================== */
form {
margin-bottom: 20px; }
fieldset {
margin-bottom: 20px; }
input[type="text"],
input[type="password"],
input[type="email"],
textarea,
select {
border: 1px solid #ccc;
padding: 6px 4px;
outline: none;
-moz-border-radius: 2px;
-webkit-border-radius: 2px;
border-radius: 2px;
font: 13px "HelveticaNeue", "Helvetica Neue", Helvetica, Arial, sans-serif;
color: #777;
margin: 0;
width: 210px;
max-width: 100%;
display: block;
margin-bottom: 20px;
background: #fff; }
select {
padding: 0; }
input[type="text"]:focus,
input[type="password"]:focus,
input[type="email"]:focus,
textarea:focus {
border: 1px solid #aaa;
color: #ffcc00;
-moz-box-shadow: 0 0 3px rgba(0,0,0,.2);
-webkit-box-shadow: 0 0 3px rgba(0,0,0,.2);
box-shadow: 0 0 3px rgba(0,0,0,.2); }
textarea {
min-height: 60px; }
label,
legend {
display: block;
font-weight: bold;
font-size: 13px; }
select {
width: 220px; }
input[type="checkbox"] {
display: inline; }
label span,
legend span {
font-weight: normal;
font-size: 13px;
color: #444; }
/* #Misc
================================================== */
.remove-bottom { margin-bottom: 0 !important; }
.half-bottom { margin-bottom: 10px !important; }
.add-bottom { margin-bottom: 20px !important; }
[/sourcecode]
Now we can use the jekyll command to generate the static content and review it. In a subsequent post I’ll cover how to run this via the server to test out what the page would look like with all relative links.
[sourcecode language=”bash”]
jekyll
[/sourcecode]
…and after execution the following message will display at the command line.
[sourcecode language=”bash”]
WARNING: Could not read configuration. Using defaults (and options).
No such file or directory – /Users/adronhall/Codez/Me/_config.yml
Building site: /Users/adronhall/Codez/Me -> /Users/adronhall/Codez/Me/_site
Successfully generated site: /Users/adronhall/Codez/Me -> /Users/adronhall/Codez/Me/_site
[/sourcecode]
This warning isn’t super relevant just yet. We’ve got a basic generated jekyll site localted at /Users/adronhall/Codez/Me/_site where that path is your path to the _static directory within your git repository. Once the content is verified via the _static directory the site is ready to post.
[sourcecode language=”bash”]
git add -A
git commit -m ‘Adding the index.html and basic layouts template for a starter jekyll site.’
git push origin gh-pages
[/sourcecode]
After it pushes, it may take up to 10 minutes before it displays properly. This is likely because Github has to queue the jekyll command to run to statically generate your content for the gh-pages branch. To view the newly created site and see if the generation has occurred navigate to http://yourusername.github.io/Me/. In the case of my personal site, it’s http://adron.github.io/Me/. Also note, at this stage the page and CSS look pretty bad. But work with me here, we’re going to add elements that will align the theme with the actual project as things come together. This css page however will be a core base for everything we’ll work through.
This concludes part 1. I’ve covered created the Github Pages automatically created templates pages, how to delete those and setup a manually created jekyll site. This gives a huge amount of control to the site, to edit, add blogs or other jekyll and of course JavaScript capable site features.
In subsequent parts of this blog series I’ll cover diving into deployment to AWS (Amazon Web Services), how to setup beanstalk via AWS, setting up Riak for a data back end and how to distribute this web application and Riak to offer a massively scalable site architecture (because you never know when you’ll get slammed with page hits on your personal site righ!) Among all these massive distributed how-to topics I’ll also dive into how exactly I’ve got a template and node.js application up and running via AWS and using Riak. So lots of material and information coming in the subsequent parts of this blog series.
🙂 Please subscribe (see upper right follow link to get emails, and no, you’ll get NO spam from me, just blog entries), comment below if you have any questions & let me know if you’d like me to add in any other how-to articles. Thanks & Enjoy!
You must be logged in to post a comment.