
The gist from the video:
Ways To Cleanup Docker Containers & Images
The gist from the video:
The gist from the video:
There’s likely a million introductions to Minikube, but I wanted one of my own. Thus, here you go! Minikube is basically Kubernetes light that runs on your own machine. Albeit, it does this similarly to how Docker used to do it, via a virtual machine. Thus, you can do some things with it but if you want to get serious you’ll still need to spool up a proper cluster somewhere as it will start to bog down your machine with any heavy workloads.
Linux Direct:
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 \
&& sudo install minikube-linux-amd64 /usr/local/bin/minikubeLinux Debian:
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 \
&& sudo install minikube-linux-amd64 /usr/local/bin/minikubeLinux Red Hat:
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-1.4.0.rpm \
&& sudo rpm -ivh minikube-1.4.0.rpmminikube start will start a minikube instance, pulling images, resources, kubelets, kubeadm, dashboard, and all those resources.

minikube stop brings the minikube service to a stop, allowing for restart later.

minikube delete will delete the minikube. This will delete any of the content or related collateral that was running in the minikube.
![]()
minikube start this is the way to restart a minikube instance after you’ve stopped the instance. It’s also the way start a minikube, as shown above.

If you want a named minikube instance, use the -p switch, with a command like minikube start -p adrons-minikube.

To check out the dashboard, that pretty Google dashboard for Kubernetes, run minikube dashboard to bring that up.


To get a quick update on the current state of the minikube instance just run minikube status.

This is, albeit I may be mistaken, this is a Linux only feature. Run minikube start --vm-driver=none and it’ll kick off a minikube right there on your local machine.

References:
 In this blog entry I’m going to detail the exact configuration and cover in some additional details the collateral resources you can expect to find once the configuration is executed against with Terraform. For the repository to this write up, I create our_new_world available on Github.
In this blog entry I’m going to detail the exact configuration and cover in some additional details the collateral resources you can expect to find once the configuration is executed against with Terraform. For the repository to this write up, I create our_new_world available on Github.
First things first, locally you’ll want to have the respective CLI tools installed for Google Cloud Platform, Terraform, and Kubernetes.
gcloud components install kubectl command.Now that all the prerequisites are covered, let’s dive into the specifics of setup.
 If you take a look at the Google Cloud Platform Console, it’s easy to get a before and after view of what is and will be built in the environment. The specific areas where infrastructure will be built out for Kubernetes are in the following areas, which I’ve taken a few screenshots of just to show what the empty console looks like. Again, it’s helpful to see a before and after view, it helps to understand all the pieces that are being put into place.
If you take a look at the Google Cloud Platform Console, it’s easy to get a before and after view of what is and will be built in the environment. The specific areas where infrastructure will be built out for Kubernetes are in the following areas, which I’ve taken a few screenshots of just to show what the empty console looks like. Again, it’s helpful to see a before and after view, it helps to understand all the pieces that are being put into place.
The first view is of the Google Compute Engine page, which currently on this account in this organization I have no instances running.

This view shows the container engines running. Basically this screen will show any Kubernetes clusters running, Google just opted for the super generic Google Container Engine as a title with Kubernetes nowhere to be seen. Yet.

Here I have one ephemeral IP address, which honestly will disappear in a moment once I delete that forwarding rule.

These four firewall rules are the default. The account starts out with these, and there isn’t any specific reason to change them at this point. We’ll see a number of additional firewall settings in a moment.

Load balancers, again, currently empty but we’ll see resources here shortly.

Alright, that’s basically an audit of the screens where we’ll see the meat of resources built. It’s time to get the configurations built now.
Using Terraform to build a Kubernetes cluster is pretty minimalistic. First, as I always do I add a few files the way I like to organize my Terraform configuration project. These files include:
In the .gitignore I add just a few items. Some are specific to my setup that I have and IntelliJ. The contents of the file looks like this. I’ve included comments in my .gitignore so that one can easily make sense of what I’m ignoring.
# A silly MacOS/OS-X hidden file that is the bane of all repos.
.DS_Store
# .idea is the user setting configuration directory for IntelliJ, or more generally Jetbrains IDE Products.
.idea
.terraform
The next file I write up is the connections.tf file.
provider "google" {
credentials = "${file("../secrets/account.json")}"
project = "thrashingcorecode"
region = "us-west1"
}
The path ../secrets/account.json is where I place my account.json file with keys and such, to keep it out of the repository.
The project in GCP is called thrashingcorecode, which whatever you’ve named yours you can always find right up toward the top of the GCP Console.
![]()
Then the region is set to us-west1 which is the data centers that are located, most reasonably to my current geographic area, in The Dalles, Oregon. These data centers also tend to have a lot of the latest and greatest hardware, so they provide a little bit more oompf!
The next file I setup is the README.md, which you can just check out in the repository here.
Now I setup the variables.tf and the terraform.tfvars files. The variables.tf includes the following input and output variables declared.
// General Variables
variable "linux_admin_username" {
type = "string"
description = "User name for authentication to the Kubernetes linux agent virtual machines in the cluster."
}
variable "linux_admin_password" {
type ="string"
description = "The password for the Linux admin account."
}
// GCP Variables
variable "gcp_cluster_count" {
type = "string"
description = "Count of cluster instances to start."
}
variable "cluster_name" {
type = "string"
description = "Cluster name for the GCP Cluster."
}
// GCP Outputs
output "gcp_cluster_endpoint" {
value = "${google_container_cluster.gcp_kubernetes.endpoint}"
}
output "gcp_ssh_command" {
value = "ssh ${var.linux_admin_username}@${google_container_cluster.gcp_kubernetes.endpoint}"
}
output "gcp_cluster_name" {
value = "${google_container_cluster.gcp_kubernetes.name}"
}
In the terraform.tfvars file I have the following assigned. Obviously you wouldn’t want to keep your production Linux username and passwords in this file, but for this example I’ve set them up here as the repository sample code can only be run against your own GCP org service, so remember, if you run this you’ve got public facing default linux account credentials exposed right here!
cluster_name = "ournewworld"
gcp_cluster_count = 1
linux_admin_username = "frankie"
linux_admin_password = "supersecretpassword"
Now for the meat of this effort. The kubernetes.tf file. The way I’ve set this file up is as shown.
resource "google_container_cluster" "gcp_kubernetes" {
name = "${var.cluster_name}"
zone = "us-west1-a"
initial_node_count = "${var.gcp_cluster_count}"
additional_zones = [
"us-west1-b",
"us-west1-c",
]
master_auth {
username = "${var.linux_admin_username}"
password = "${var.linux_admin_password}}"
}
node_config {
oauth_scopes = [
"https://www.googleapis.com/auth/compute",
"https://www.googleapis.com/auth/devstorage.read_only",
"https://www.googleapis.com/auth/logging.write",
"https://www.googleapis.com/auth/monitoring",
]
labels {
this-is-for = "dev-cluster"
}
tags = ["dev", "work"]
}
}
With all that setup I can now run the three commands to get everything built. The first command is terraform init. This is new with the latest releases of Terraform, which pulls down any of the respective providers that a Terraform execution will need. In this particular project it pulls down the GCP Provider. This command only needs to be run the first time before terraform plan or terraform apply are run, if you’ve deleted your .terraform directory, or if you’ve added configuration for something like Azure, Amazon Web Services, or Github that needs a new provider.

Now to ensure and determine what will be built, I’ll run terraform plan.

Since everything looks good, time to execute with terraform apply. This will display output similar to the terraform plan command but for creating the command, and then you’ll see the countdown begin as it waits for instances to start up and networking to be configured and routed.

While waiting for this to build you can also click back and forth and watch firewall rules, networking, external IP addresses, and instances start to appears in the Google Cloud Platform Console. When it completes, we can see the results, which I’ll step through here with some added notes about what is or isn’t happening and then wrap up with a destruction of the Kubernetes cluster. Keep reading until the end, because there are some important caveats about things that might or might not be destroyed during clean up. It’s important to ensure you’ve got a plan to review the cluster after it is destroyed to make sure resources and the respective costs aren’t still there.
In the console click on the compute engine option.

I’ll start with the Compute Engine view. I can see the individual virtual machine instances here and their respective zones.
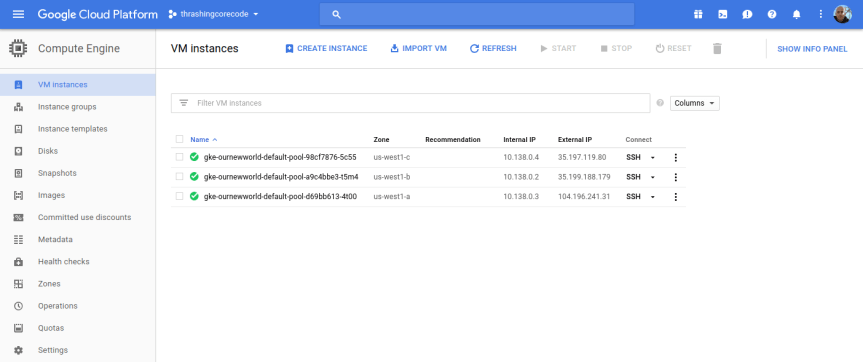
Looking at the Terraform file confiugration I can see that the initial zone to create the cluster in was used, which is us-west1-a inside the us-west1 region. The next two instances are in the respective additional_zones that I marked up in the Terraform configuration.
additional_zones = [
"us-west1-b",
"us-west1-c",
]
You could even add additional zones here too. Terraform during creation will create an additional virtual machine instance to add to the Kubernetes cluster for each increment that initial_node_count is set to. Currently I set mine to a variable so I could set it and other things in my terraform.tfvars file. Right now I have it set to 1 so that one virtual machine instance will be created in the initial zone and in each of the designated additional_zones.
Beyond the VM instances view click on the Instance groups, Instance templates, and Disks to seem more items setup for each of the instances in the respective deployed zones.
If I bump my virtual machine instance count up to 2, I get 6 virtual machine instances. I did this, and took a screenshot of those instances running. You can see that there are two instances in each zone now.

Note that an instance group is setup for each zone, so this group kind of organizes all the instances in that zone.

Like the instance groups, there is one template per zone. If I setup 1 virtual machine instance or 10 in the zone, I’ll have one template that describes the instances that are created.


To SSH into any of these virtual machine instances, the easiest way is to navigate into one of the views for the instances, such as under the VM instances section, and click on the SSH button for the instance.
Then a screen will pop up showing the session starting. This will take 10-20 seconds sometimes so don’t assume it’s broken. Then a browser based standard looking SSH terminal will be running against the instance.


This comes in handy if any of the instances ends up having issues down the line. Of all the providers GCP has made connecting to instances and such with this and tools like gcloud extremely easy and quick.
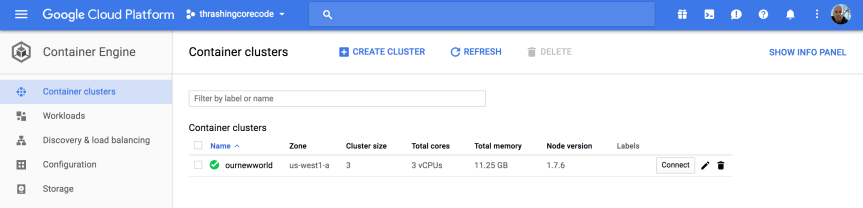
In this view we have cluster specific information to check out.

Once the cluster view comes up there sits the single cluster that is built. If there are additional, they display here just like instances or other resources on other screens. It’s all pretty standard and well laid out in Google Cloud Platform fashion.
The first thing to note, in my not so humble opinion, is the Connect button. This, like on so many other areas of the console, has immediate, quick, easy ways to connect to the cluster.

Gaining access to the cluster that is now created with the commands available is quick. The little button in the top right hand corner copies the command to the copy paste buffer. The two commands execute as shown.
gcloud container clusters get-credentials ournewworld --zone us-west1-a --project thrashingcorecode
and then
kubectl proxy

With the URI posted after execution of kubectl proxy I can check out the active dashboard rendered for the container cluster at 127.0.0.1:8001/ui.
IMPORTANT NOTE: If the kubectl version isn’t up to an appropriate parity version with the server then it may not render this page ok. To ensure that the version is at parity, run a kubectl version to see what versions are in place. I recently went through troubleshooting this scenario which rendered a blank page. After trial and error it came down to version differences on server and client kubectl.

I’ll dive into more of the dashboard and related things in a later post. For now I’m going to keep moving forward and focus on the remaining resources built, in networking.

Once the networking view renders there are several key tabs on the left hand side; External IP addresses, Firewall rules, and Routes.
Setting and using external IP addresses allow for routing to the various Kubernetes nodes. Several ephemeral IP addresses are created and displayed in this section for each of the Kubernetes nodes. For more information check out the documentation on reserving a static external IP address and reserving an internal IP address.

In this section there are several new rules added for the cluster. For more information specific to GCP firewall rules check out the documentation about firewall rules.

Routes are used to setup paths mapping an IP range to a destination. Routes setup a VPC Networks where to send packets for a particular IP address. For more information about documentation route details.

Each of these sections have new resources built and added as shown above. More than a few convention based assumptions are made with Terraform.
In my next post I’ll dive into some things to setup once you’ve got your Kubernetes cluster. Setting up users, getting a continuous integration and delivery build started, and more. I’ll also be writing up another entry, similar to this for AWS and Azure Cloud Providers. If you’d like to see Kubernetes setup and a tour of the setup with Terraform beyond the big three, let me know and I’ll add that to the queue. Once we get past that there are a number of additional Kubernetes, containers, and dev specific posts that I’ll have coming up. Stay tuned, subscribe to the blog feed or follow @ThrashingCode for new blog posts.
Resources:
Recently a post from @Gigabarb popped up on the ole’ Twitter that started a micro-storm of twitter responses.
Ok tech users. Who out there is using a PaaS? For realz. Serious question.
— Barb Darrow (@gigabarb) November 21, 2013
This got me thinking about a number of things and I started to write her an email specifically, but realized I should really just blog it. After all, the topic is actually part of what should be the public conversation. It’s about the changing world of technology, which we’re all part of…
Barb, just shortly after the tweet above was posted, this other tweet altered what information I might provide her. @TheSteve0 had responded with some items, which @GigaBarb then responded with
@TheSteve0 those names are the same … looking for more…thanks tho
— Barb Darrow (@gigabarb) November 21, 2013
Now, not to pick on OpenShift & Red Hat (the effort @TheSteve0 is working with), because they have a great open source effort going on around this PaaS Technology, but Barb had a point. If Cloud Foundry responded with something like this, she’d still have a point. The only companies that continually sign up new companies is AWS & Beanstalk (ok, so they don’t call it PaaS, it gets you to the same place – arguably better than most of the others), a little bit at Windows Azure and a few companies pop up every once in a long while that might take Cloud Foundry or OpenShift and run with it. Most of the early adopters are already on board and most that might get on board are still mostly just waiting in the sidelines.
This fact is frustrating for those
in the space that want to see more penetration, but for those that arent’ technically in the space, it seems kind of like ASP. Oh wait, I should add context now, ASPs as in Application Service Providers. The technology from the beginning of the 21st century similar in many ways to what is dubbed SaaS now. At the time it could have been revolutionary. However at the time nobody picked it up either. This is similar to what PaaS is seeing. However…
![]()
I have a theory of what will happen to PaaS Tech, it is similar to ASP Tech. PaaS will keep plundering along in odd ways, and eventually one day, it will become a mainstream tech. Right now however it will remain limited. In that same turn, by the time it becomes a common tech, it’ll be called something else.
Here’s a few reasons. One, is that many developers see PaaS and their response, especially if they’re seasoned developers with more than a few years under their belt, is to respond will immediate apprehension to the tech. It removes key elements of what they want to control. It hides things they can’t actually get to and it abstracts in ways that don’t always make sense. The result is that many senior devs stay away from pure PaaS offerings and instead use it only for prototyping, but production gets something totally different. I’ve been there more than a few times myself.
However, the result of what most senior devs end up with, when they get their continuous integration and development environments running at full tilt, is exactly what PaaS is attempting to promise. There are some companies, with senior devs, and extremely intelligent members that have taken PaaS and effectively implemented it into their continuous integration and delivery environment giving them strengths that most companies can only imagine to have.
One of those companies is lucky and smart enough to have Jonathan Murray @adamalthus heading up efforts. On his team he also has Dave McCrory @mccrory and Brian McClain @brianmmclain. To boot, they are close to the Cloud Foundry team (and @wattersjames, who cuts a path when there are issues) and keep a solid effort going working with key partners such as @Tier3 (now part of CenturyLink) and other companies that help bring together one of the most strategically and tactically relevant PaaS deployments to date.
Other PaaS deployments are questionable for various reasons, they’re trying, but they aren’t there. At least not the types of companies and efforts that Barb was looking for. So really, if there is another out there that’s hiding, but wants serious street cred. A boost to hiring serious A grade talent, and to push forward past competitors, please let us know. Let me know, let Barb know and let’s hear about what you’re doing. If a company is hiding their implementation and doesn’t want to be part of the community, then fine, they can stay hidden and not gain the benefit of the community that presses forward beyond them. But I would love to hear from those that I might have missed, that want to push forward, so ping me. Ping Barb, we’ll get word out there and get developers checking out and making sure your company is getting it done! 😉
PaaS is nice. If your company can get it deployed and use it effectively, the you’re going to push forward fast in many regards. Deployments, savings, code cleanliness, effective separation of concerns and abstraction at a systems level are some of the things you can expect from a good PaaS implementation. Sometimes however, as the senior devs I mentioned pointed out, you give up control and certain levels of abstraction. However almost all senior devs understand that they want the ability to abstract at the levels that PaaS enables. They want to break apart the app cleanly at the system level from the software level. No reason for an app to know where or what a hard drive is doing right? That’s a rhetorical question, onward with the topic…
Docker has entered the market with a BOOM, part of the abstraction level that enables PaaS tooling in the first place. This tool enables a team to jump into the code or to just deploy the tool to abstract at a PaaS level, but to build the elements that they need specifically. The components are able to be brought together in a composite way that provides all the advantages of PaaS, while put together specifically for the problem space that the team is attacking. For environments that don’t make cookie cutter apps that fit perfectly to PaaS tooling as it is, that needs that little bit extra control of the environment, Docker is the perfect tool to bring those pieces together.
So really, is Docker and containerization that new word (from a technically old tech! lolz), that new tech, that’s going to bring PaaS into the mainstream as the standard implementation? Is it going to make PaaS become containerization when we developers talk about it? It could very well be the next big step. It could be that last mile coverage that devs want to push environments into a PaaS Tech ecosystem and make full use of hardware, software and move to the next stage of application development. Could it? Will it?
Personally I’m ready for the next stage of the whole PaaS thing, are you?
Next up on other thought patterns, WTF are people using Oracle for still when mariadb and postgres mean their freedom to innovate, move forward and surpass their competition.
Over the next dozen or so few days I’ll be ramping up on Docker, where my gaps are and where the project itself is going. I’ve been using it on and off and will have more technical content, but today I wanted to write a short piece about what, where, who and how Docker came to be.
As an open source engine Docker automates deployment of lightweight, portable, resilient and self-sufficient containers that run primarily on Linux. Docker containers are used to contain a payload, encapsulate that and consistently run it on a server.
This server can be virtual, on AWS or OpenStack, in clusters, public instances or private, bare-metal servers or wherever one can get an operating system to run. I’d bet it would show up on an Arduino cluster one of these days. 😉
User cases for Docker include taking packaging and deployment of applications and automating it into a simple container bundle. Another is to build PaaS style environments, lightweight that scale up and down extremely fast. Automate testing and continuous integration and deployment, because we all want that. Another big use case is simply building resilient, scalable applications that then can be deployed to Docker containers and scaled up and down rapidly.
The creators of Docker formed a company called dotCloud that provided PaaS Services. On October 29th, 2013 however they changed the name from dotCloud to Docker Inc to emphasize the focus change from the dotCloud PaaS Technology to the core of dotCloud, Docker itself. As Docker became the core of a vibrant ecosystem the founders of dotCloud chose to focus on this exciting new technology to help guide and deliver on an ever more robust core.

The community of docker has been super active with a dramatic number of contributors, well over 220 now, most who don’t work for Docker and they’ve made a significant percentage of the commits to the code base. As far as the repo goes, it has been downloaded over a 100,000 times, yup, over a hundred. thousand. times!!! It’s container tech, I’m still impressed just by this fact! On Github the repo has thousands of starred observers and over 15,000 people are using Docker. One other interesting fact is the slice of languages, with a very prominent usage of Go.

Overall the Docker project has exploded in popularity, which I haven’t seen since Node.js set the coder world on fire! It’s continuing to gain steam in how and in which ways people deploy and manage their applications – arguably more effectively in many ways.

The community is growing accordingly too, not just a simple push by Docker/dotCloud itself, but actively by grass roots efforts. One is even sprung up in Portland in the Portland Docker Meetup.

One of the best ways to describe docker (which the Docker team often uses, hat tip to the analogy!) and containers in general is to use a physical parallel. One of the best stories that is a great example is that of the shipping and freight industry. Before containers ships, trains,

trucks and buggies (ya know, that horses pulled) all were loaded by hand. There wasn’t any standardization around movement of goods except for a few, often frustrating tools like wooden barrels for liquids, bags for grains and other assorted things. They didn’t mix well and often were stored in a way that caused regular damage to good. This era is a good parallel to hosting applications on full hypervisor virtual machines or physical machines with one operating system. The operating system kind of being the holding bay or ship, with all the freight crammed inside haphazardly.

When containers were introduced like the shiny blue one shown here, everything began a revolutionary change. The manpower dramatically

dropped, injuries dropped, shipping became more modular and easy to fit the containers together. To put it simply, shipping was revolutionized through this invention. In the meantime we’ve all benefitted in some way from this change. This can be paralleled to the change in container technology shifting the way we deploy and host applications.
Next post, coming up in just a few hours “Docker, Containers Simplified!”
You must be logged in to post a comment.